Table partitioning
- Database partition là gì và tại sao cần dùng?
Đúng như tên gọi, table partitioning là kĩ thuật phân chia một “table” thành nhiều “partition” nhỏ hơn. Vì sao phải làm vậy?
Đầu tiên ta cần phải hiểu bản chất của việc thực hiện các câu query đều là scan table => do đó table càng lớn => scan càng nhiều => giảm performance kể cả có áp dụng kĩ thuật đánh index.
Lấy 1 ví dụ: Giả sử ta có 1 bảng tên là khach_hang, lưu trữ dữ liệu của toàn bộ khách hàng từ lúc triển khai hệ thống đến hiện tại. Khi muốn lấy 1 dữ liệu khách hàng có thoi_gian_mua_hang là năm 2017 chẳng hạn, PostgreSQL cũng phải quét dữ liệu toàn bộ bảng để lấy ra dữ liệu ta cần.
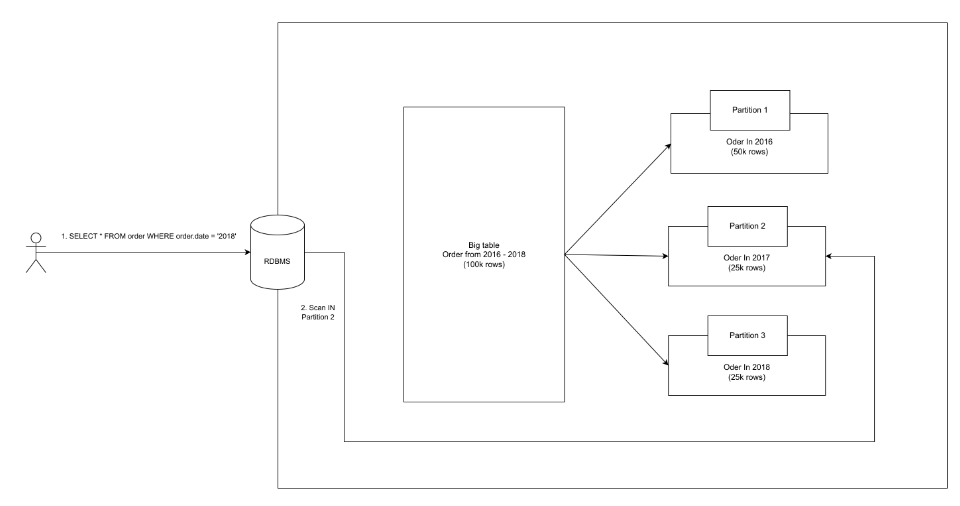
Nếu ta dùng kỹ thuật partition để chia nhỏ bảng ra theo tiêu chí thoi_gian_mua_hang, thì lúc đó, mỗi khối dữ liệu nhỏ là dữ liệu cho 1 năm (VD: 2016, 2017, 2018,…) hay còn gọi là partition. Khi đó, bạn muốn tìm dữ liệu nào đó thuộc năm 2017, chỉ có partition của năm 2017 được quét thôi, chứ không phải toàn bộ bảng.
Có 2 loại table partitioning đó là horizontal partitioning và veritical partitioning
1.1. Horizontal partitioning
Ví dụ ở ngay phía trên chính là đang áp dụng horizontal partitioning, lấy 1 ví dụ khác:

Ví dụ trong ngày khai giảng, thầy giáo A đi nhận lớp, lớp học đấy có 40 học sinh. Ngày đầu nhận lớp, thầy giáo A chưa thể nhớ tên các học sinh, nhưng cần tìm ra một bạn nữ tên “Nguyễn Thị Thùy”, vậy thì chẳng lẽ thầy A phải đi đến từng bàn và hỏi tên từng 40 học sinh?
Trên thực tế, do đã đoán được “Nguyễn Thị Thùy” phải là tên một bạn nữ do có chữ “Thị” trong đó, vậy thầy chỉ cần đi tìm bạn đó trong 10 bạn nữ của lớp mà thôi.
Đó chính là tư tưởng của table partitioning. Trong trường hợp này, ta có bảng Student với 40 rows, nhưng áp dụng partitioning, ta có thể chia bảng Student thành 2 bảng nhỏ hơn theo giới tính “Nam” và “Nữ”. Sau này nếu muốn tìm một bạn nữ thì chỉ cần scan trên bảng “Nữ” mà thôi.
Nếu có thêm học sinh vào lớp, chỉ cần sắp xếp bạn đó vào đúng nhóm là ok. Trên thực tế, việc thay đổi giới tính gần như không xảy ra, tuy nhiên nếu xảy ra thì việc cần làm là sắp xếp bạn đó về đúng nhóm của mình là xong.
Vậy thì nó khác gì với việc áp dụng thêm điều kiện “where gender = ‘Nữ’” vào câu query
Đó là vì thêm where vào thực ra nó sẽ như thế này, đó là thay vì thầy giáo A sẽ chỉ đi hỏi từng học sinh là “Em tên gì”? Mà còn chèn thêm câu “Em có phải là nữ không???” vào, kể cả đứa đang được hỏi là một thằng con trai (cạn lời). Vậy thì bản chất cũng phải đi dò hết 40 học sinh, trong khi cách kia chỉ cần dò 10 đứa.

Horizontal partitioning có những ưu điểm sau:
+ Giới hạn vùng dữ liệu phải scan trên table trong một vài trường hợp. Nếu ta cần tìm một học sinh tên John Doe không phân biệt giới tính thì việc partition như ví dụ trên không đem lại hiểu quả.
+ Partition table cũng giống như một table thường nên ta có thể thực hiện index cho nó. Dẫn đến việc tốn ít cost hơn để maintain index table => do số lượng record ít hơn.
+ Ngoài ra, việc xóa các dữ liệu trên partition table sẽ nhanh hơn và không ảnh hưởng đến các partition khác.
Với những ưu điểm trên, ta cần lưu ý khi thực hiện horizontal partitioning để đạt hiệu quả tối đa:
+ Áp dụng với các table rất lớn. Thường là quá size của memory.
+ Việc partition trên điều kiện nào phải dựa vào tính chất và tần suất của các query.
1.2. Vertical partitioning
Nếu như horizontal pertitioning là chia theo điều kiện của từng rows insert vào thì vertical sẽ đi chia theo column.
Trên thực tế, vertical partitioning đã vô tình được thực hiện khi chúng ta design database rồi. (Bằng việc chúng ta chia tách các bảng khi thiết kế)
Ví dụ khi thiết kế hệ thống quản lý nhân viên, một nhân viên sẽ có các thông tin (id, fullname, address, balance)
=> Ta sẽ tách thành 2 bảng là NhanVien và BangLuong, vì bản chất dữ liệu bên trong 2 bảng này được dùng theo cách khác nhau:
NhanVien:
+ id
+ fullname
+ address
BangLuong
+ employee_id
+ balance
Vậy lợi ích của vertical partitioning là gì?
Trước tiên cần hiểu về cách data được lưu trữ xuống disk (HDD/SSD). Về cơ bản, các records được lưu thành một khối dữ liệu có độ lớn gần tương tự như nhau được gọi là block. Do đó, nếu một table chứa số lượng column ít đồng nghĩa với việc tăng đương số lượng records lưu trữ trên một block. Như vậy nếu query các column trong cùng block, các xử lý tính toán I/O sẽ giảm đi phần nào dẫn tới việc tăng performance.
Trong thực tế, vertical partitioning nên được chú ý ngay từ khi design database vì việc này ảnh hưởng trực tiếp đến cách query và vận hành hệ thống do phải chia thành các table thực.
Horizontal partitioning đơn giản hơn một chút tuy nhiên vẫn cần dừng hệ thống trong 1 khoảng thời gian để làm các thao tác sau:
- Back-up data cũ.
- Tạo partition table.
- Insert data vào table mới.
- Các kiểu horizontal partition
2.1. Horizontal partitioning by range
Bản chất của partitioning là phân chia ra các partition table dựa trên điều kiện phân vùng partition key. Với partition by range, điều kiện partition có thể là:
+ Phân chia theo thời gian.
+ Phân chia theo numeric từ 1 đến 5, 6 đến 10…
+ Phân chia theo bảng chứ cái A, B, C; D, E, F…
Khi thực hiện range partition ta quan tâm đến giá trị min và max của mỗi partition để thực hiện việc phân chia. Ví dụ table ENGINEER có thông tin về ngày bắt đầu làm việc (start_date), ta có thể dựa trên column này để phân chia partition theo từng quý. Ta cần backup data trước khi tạo partition.
DROP TABLE ENGINEER;
CREATE TABLE ENGINEER
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL
) PARTITION BY RANGE(started_date);
CREATE TABLE ENGINEER_Q1_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-01-01') TO ('2020-04-01');
CREATE TABLE ENGINEER_Q2_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-04-01') TO ('2020-07-01');
CREATE TABLE ENGINEER_Q3_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-07-01') TO ('2020-10-01');
CREATE TABLE ENGINEER_Q4_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-10-01') TO ('2020-12-31');
Có một đặc biệt là ta phải drop table trước khi tạo partition, do đó hãy nhớ backup trước.
Dưới đây là các partition đã tạo:

Ta thử insert 100k records vào: https://drive.google.com/file/d/19JXghNjMOjZ66PpmvDjQoPawwlNTgIl5/view

Đầu tiên ta sẽ thử tìm employee có id = 10:
EXPLAIN SELECT * FROM ENGINEER WHERE id = 10;

Có thể thấy vẫn phải đi seq scan hết cả 4 partition => chưa có gì đặc biệt
Chưa thấy có gì đặc biệt, thử tìm kiếm các engineer bắt đầu làm việc từ Apr 01, 2020:
EXPLAIN SELECT \* FROM ENGINEER WHERE started_date = '2020-04-01';

Kết quả cho ra rất tuyệt vời, lúc này query plan chỉ cần scan trên đúng partition của q2 (vì 2020-04-01 là thuộc quý 2) => cost giảm xuống đáng kể.
Mặc dù ta không specific chỉ định partition engineer_q2_2020 nhưng PostgreSQL biết điều đó và tối ưu luôn cho chúng ta. Câu query trên tương tự với:
EXPLAIN SELECT \* FROM ENGINEER_Q2_2020 WHERE started_date = '2020-04-01';
Mỗi partition được coi là một table riêng biệt và kế thừa các đặc tính của table. Ta hoàn toàn có thể thêm index cho từng partition để tăng performance cho query, được gọi là local index. Hoặc thêm index cho parent table, được gọi là global index.
Có một điều cần phải lưu ý, đó là không thể tạo primary key hay unique trên column của table được partitioning, ví dụ:
CREATE TABLE TEST_PK
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL,
PRIMARY KEY (id)
) PARTITION BY RANGE(started_date);
CREATE TABLE TEST_UNQ
(
id bigserial UNIQUE NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL
) PARTITION BY RANGE(started_date);


Tạo pk hay unique cho table được partitioning chỉ được khi ta bỏ thêm partition key vào trong primary key hay unique, ví dụ như này sẽ được:
CREATE TABLE TEST_PK
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL,
PRIMARY KEY (id, started_date)
) PARTITION BY RANGE(started_date);
Do ta có thêm partition key là started_date vào bên trong primary key (id, started_date), với unique cũng tương tự.
Vì sao không thể tạo constraint PK hoặc unique (single column without partition column combination) với parent partition table?
Bản chất của partition là chia một logical table ra thành nhiều small physical pieces. Lúc này table ENGINEER ban đầu mà ta định nghĩa chỉ là abstract table, định nghĩa ra các partition bao gồm những column nào, trường dữ liệu gì. Việc quyết định constraint unique sẽ apply cho toàn bộ các partition, điều đó khiến cho các partition phải liên hệ với nhau để check một value có là unique hay không, nó làm phá vỡ đi ý nghĩa partition ban đầu.
Ví dụ: nếu ta đánh unique cho ‘first_name’ trong bảng employee, thì nếu insert data mới thì db nó phải scan hết trên từng partition khác để check xem có unique hay không
P/S: có thể tạo constraint PK/Unique trong trường hợp constraint đó phải bao gồm các partition columns. Tuy nhiên nó không thỏa mãn yêu cầu mong muốn ban đầu. Với partitioning, dữ liệu được chia nhỏ thành các phần riêng biệt (partitions), và một số cơ sở dữ liệu không thể kiểm tra unique constraint trên toàn bộ các partitions cùng lúc. Điều này là do mỗi partition hoạt động như một bảng riêng biệt, và unique constraint chỉ có thể được thực hiện trên một partition cụ thể thay vì toàn bộ bảng.
Với ví dụ trên, ta có tổng cộng 4 partitions cho 4 quý của năm 2020. Nếu insert hoặc update một record không thuộc năm 2020 thì chuyện gì sẽ xảy ra:
UPDATE ENGINEER SET started_date = ‘2021-01-01’;
INSERT INTO ENGINEER(first_name, last_name, gender, country_id, title, started_date, created)
VALUES(‘Hermina’, ‘Kuhlman’, 3, 229, ‘Backend Engineer’, ‘2021-09-23’, current_timestamp);

Không thể được, vì postgres không tìm được partition nào thích hợp để insert vào, vậy ta cần một bảng riêng để chứa các record không thuộc điều kiện của partition key, gọi là default partition:
CREATE TABLE ENGINEER_DEFAULT_PARTITION PARTITION OF ENGINEER DEFAULT;
Lúc này khi chạy lại câu insert kia, thì nó sẽ được lưu vào default partition:

Vài câu hỏi khác được đặt ra:
- Có thể tạo một partition mới trong quá trình runtime không?
=> Trả lời: có thể, giống như ví dụ tạo default partition ban nãy
- Có thể có nhiều hơn 1 partition chứa cùng một khoảng thời gian không? Ví dụ partition: 2020-01-01:2020-04-01 và partition: 2020-02-01:2020-05-01.
=> Không thể được

Ví dụ: khoảng partition từ 1/9/2020 - 30/11/2020 đã bị trùng vài ngày với partition_q3 => lỗi
- Có thể drop một partition trong quá trình runtime mà giữ nguyên data của partition đó không?
=> Không thể, kể cả có default partition hay không:

2.2. Horizontal partitioning by list
Với list partitioning, việc phân chia ra các partition dựa trên key được định nghĩa dưới dạng list of value. Ví dụ với table ENGINEER, các engineer có title Backend Engineer, Frontend Engineer, Fullstack Engineer nhóm vào thành một partition; BA và QA một partition; còn lại là default partition.
DROP TABLE ENGINEER CASCADE;
CREATE TABLE ENGINEER
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL
) PARTITION BY LIST(title);
CREATE TABLE ENGINEER_ENGINEER PARTITION OF ENGINEER FOR VALUES
IN ('Backend Engineer', 'Frontend Engineer', 'Fullstack Engineer');
CREATE TABLE ENGINEER_BA_QA PARTITION OF ENGINEER FOR VALUES
IN ('BA', 'QA');
CREATE TABLE ENGINEER_DEFAULT PARTITION OF ENGINEER DEFAULT;
Chạy như trên sẽ tạo ra 3 partition,
Partition engineer_ba_qa sẽ chỉ chứa các employee có title là BA hoặc QA:

Tương tự, partition engineer_engineer chỉ chứa employee có titile là Backend engineer, Frontend engineer hoặc Fullstack engineer:

Về mục đích cũng không khác gì partition by range ngoài việc chia nhỏ ra thành nhiều partition. Tuy nhiên, trường hợp áp dụng sẽ có khác nhau đôi chút: List partition phân chia table dựa trên danh sách các giá trị cho trước, không theo khoảng giá trị như range partition. Do đó, nó phù hợp phân chia dữ liệu theo những giá trị cụ thể, giống bài toán phân chia nam, nữ ở phần trước.
2.3. Horizontal partitioning by hash
Idea không có gì phức tạp, các bước thực hiện như sau:
Thực hiện hash partition key ra hash value.
Modulus để tìm partition cho record. Ví dụ record có partition key hash value = 5, tổng số lượng partition là 3 (0, 1, 2), lấy 5 % 3 = 2. Vậy record đó nằm ở partition thứ ba.
DROP TABLE ENGINEER CASCADE;
CREATE TABLE ENGINEER
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL
) PARTITION BY HASH(country_id);
CREATE TABLE ENGINEER_P1 PARTITION OF ENGINEER
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE TABLE ENGINEER_P2 PARTITION OF ENGINEER
FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE ENGINEER_P3 PARTITION OF ENGINEER
FOR VALUES WITH (MODULUS 3, REMAINDER 2);
Giải thích: (MODULUS 3, REMAINDER 1) nghĩa là sẽ chia lấy dư cho 3, nếu mà dư 1 thì sẽ bỏ vào partition này.
Như vậy với hash partition, không dễ để đoán được một record nằm ở partition nào. Cho dù có biết thuật toán hash, cũng cần thêm một vài step để biết được đáp án.
Vậy nên, hash partition phù hợp với:
+ Các dữ liệu không nhất thiết phải thuộc cùng một group để nhóm vào một partition.
+ Không cần thực hiện các lệnh đặc biệt với một nhóm data nào đó, ví dụ như drop.
+ Với hash partition, chỉ cần đạt được mục đích cố gắng chia thành nhiều partition cân bằng nhau là được. Như vậy đủ để tăng performance cho query.
=> Như vậy nói chung là, nếu dữ liệu không thể phân chia rạch ròi bằng các điều kiện nào đó => áp dụng hash partition
Ví dụ:
EXPLAIN SELECT * FROM ENGINEER WHERE COUNTRY_ID = 1;

Vì 1 % 3 dư 1 => phải nằm ở partition 3 => query plan có thể biết luôn được điều đó và handle giùm mình luôn phần này.
Vì sao Postrges biết được điều này? Nó tính toán thế nào? Đó là nhờ Partition pruning
Mặc định, partition pruning sẽ được enable, giờ ta tắt nó thử xem thế nào:
SET enable_partition_pruning = off;
EXPLAIN SELECT * FROM ENGINEER WHERE country_id = 1;
Kết quả:

Có thể thấy Postgres đã mất đi khả năng thần thánh lựa partition để lấy data, mà nó phải đi seq scan full cả 3 partition.
Nếu query plan và PostgreSQL thông minh đến vậy thì tại sao không partition toàn bộ các table để tăng query performance? Có bí ẩn gì đằng sau mà ta chưa biết không?
3. Multi level partition

Đây là kĩ thuật chia nhỏ của chia nhỏ, ví dụ một partition có thể chia nhỏ tiếp ra thành các partition nhỏ hơn nữa.
Ví dụ cho trường hợp ta có bảng employee và tạo một partition cho các employee bắt đầu làm việc vào quý 1 năm 2020:
DROP TABLE ENGINEER;
CREATE TABLE ENGINEER
(
id bigserial NOT NULL,
first_name character varying(255) NOT NULL,
last_name character varying(255) NOT NULL,
gender smallint NOT NULL,
country_id bigint NOT NULL,
title character varying(255) NOT NULL,
started_date date,
created timestamp without time zone NOT NULL
) PARTITION BY RANGE(started_date);
CREATE TABLE ENGINEER_Q1_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-01-01') TO ('2020-04-01');
CREATE TABLE ENGINEER_DF PARTITION OF ENGINEER DEFAULT;
Ví dụ, công ty này được chỉ vừa mới được thành lập vào cuối năm 2019, và vì vài lý do nào đó, công ty hết tiền chẳng hạn, nên sau quý 1 năm 2020 công ty hầu như chẳng tuyển thêm ai cả (mà có khi còn layoff cả đống dev :D ) => thế nên mọi query 95% đều tập trung vào partition ENGINEER_Q1_2020.
Vậy có vấn đề ở đây đó là chúng ta chia partition như thế chả giải quyết được vấn đề gì, vì data đã tập trung hầu hết vào partition ENGINEER_Q1_2020, và hầu hết query cũng chỉ tập trung vào partition này => phải scan một lượng dữ liệu lớn chẳng khác gì scan full table chưa partitioning.
=> Do đó, ta sẽ tiếp tục chia partition cho partition ENGINEER_Q1_2020 này:
DROP TABLE ENGINEER_Q1_2020;
CREATE TABLE ENGINEER_Q1_2020 PARTITION OF ENGINEER FOR VALUES
FROM ('2020-01-01') TO ('2020-04-01') PARTITION BY LIST(title);
CREATE TABLE ENGINEER_Q1_2020_SE PARTITION OF ENGINEER_Q1_2020
FOR VALUES IN ('Backend Engineer', 'Frontend Engineer', 'Fullstack Engineer');
CREATE TABLE ENGINEER_Q1_2020_BA PARTITION OF ENGINEER_Q1_2020
FOR VALUES IN ('BA', 'QA');
CREATE TABLE ENGINEER_Q1_2020_DF PARTITION OF ENGINEER_Q1_2020 DEFAULT;
Lúc này ta sẽ thấy hiện tượng siêu nhiên partition trong partition như hình dưới đây:

Nhìn quen không, trong của trong của trong của trong…:

Thử insert lại data và query xem thế nào:
EXPLAIN SELECT * FROM ENGINEER WHERE started_date = ‘2020-02-02’;

Có thể thấy lúc này multi level partition của chúng ta vẫn chưa phát huy hiệu quả, vẫn phải đi full scan tất cả partition do ta chưa sử dụng partition key là “title”:

Quá tuyệt vời, postgres giờ chỉ cần scan trên đúng 1 partition thoả điều kiện where mà thôi.
About this Post
This post is written by haphuthinh, licensed under CC BY-NC 4.0.
Next
Giới thiệu Postgre View
Previous
Giới thiệu và sử dụng Wal-g để thực hiện backup database và push backup file lên 3rd party service như AWS S3
Recommended Posts
Failed to load recommendations.